La primera función real del proyecto fue sigmoid. La elección no fue mía, en realidad. Sigmoid es la función de activación clásica, la que aparece en cualquier vídeo introductorio de redes neuronales, la que te encuentras en los libros antiguos de machine learning antes de que ReLU se hiciera el rey. Hay otras opciones más modernas y de hecho mejores para redes profundas, pero para una red pequeña con una sola capa oculta, sigmoid funciona perfectamente bien y tiene la ventaja gigante de que es muy fácil de derivar. Y derivar es lo que vamos a tener que hacer en backpropagation, así que cualquier facilidad es bienvenida.
La fórmula es esta:
Si la miras un momento te das cuenta de lo que hace. Si es muy grande, se va a cero, así que se va a . Si es muy negativo, se va a infinito, así que se va a . Y si , , así que . Lo que hace sigmoid es coger cualquier número de la recta real y aplastarlo entre 0 y 1, pasando por 0.5 en el origen. Es una S suave, una curva gigachad sigma.
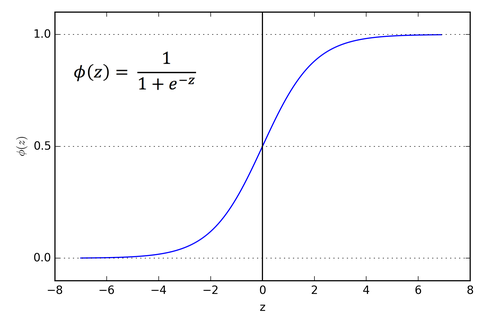
¿Por qué se usa sigmoid?
La razón principal es que aplasta los valores. Recuerda que en la fórmula central de una red, , el resultado puede ser cualquier número, positivo o negativo, grande o pequeño. Si vas pasando esos números brutos de capa en capa sin aplastarlos, se descontrolan. Acabas con neuronas que tienen activaciones de magnitudes enormes y otras que están muertas, y la red no aprende nada bueno.
Sigmoid soluciona eso de una forma muy limpia. Cualquier cosa que entre, sale como una probabilidad de activación entre 0 y 1. Es como un factor de “cuánto se enciende esta neurona”. Cero es apagada, uno es encendida al máximo, y los valores intermedios son grados de activación. Esa interpretación de “encendida o apagada” es la que conecta con la analogía biológica original de las neuronas (aunque, como dije en NN-02 Qué es una red neuronal, la analogía biológica es más un préstamo que una verdad, y jode en realidad una barbaridad).
Hay un problema con sigmoid que hay que mencionar aunque en este proyecto no afectó, pero me lo dijo una buena amiga (la IA). Cuando es muy grande o muy pequeño, la curva se aplana. La derivada en esas zonas es prácticamente cero. Y si la derivada es cero, gradient descent no puede ajustar bien los pesos en esa zona, porque la dirección que indica la derivada es prácticamente nula. Eso se llama “vanishing gradient problem” y es la razón, quizás —lo que creo— por la que en redes profundas se usa ReLU en lugar de sigmoid. Pero como esto es una red de una sola capa oculta, no llegamos a sufrir el problema. Funcionar, funciona. Así que ya está.
Derivar sigmoid a mano
Esta fue la primera derivada del proyecto y la primera donde sentí que estaba haciendo algo de matemáticas en serio, pero es un ejercicio, sin más. Y voy a contar el proceso entero porque es lo que viví.
Para derivar usé la regla del cociente. La regla del cociente dice que si tienes , su derivada es . En nuestro caso (constante, su derivada es cero) y (su derivada es , porque la derivada de es por la regla de la cadena). Aplicando la fórmula:
Hasta aquí llegué solo. Y pensé “vale, ya está, esta es la derivada de sigmoid”. La fórmula es correcta. Numéricamente es la respuesta exacta. Pero hay una cosa que no me cuadraba, porque para corroborarlo busqué en internet la solución original.
En todos los sitios que había mirado, la derivada de sigmoid se escribía como . Y mi resultado parecía completamente diferente. Pasé un buen rato confundido pensando que había hecho algo mal, comparando los signos, recalculando. La duda era legítima: ¿cómo es que mi es lo mismo que ? No se parecen ni de lejos a primera vista.
Tonto de mí, jajska. Resulta que eran exactamente lo mismo. Solo que escritos de forma distinta. El truco está en sumar y restar 1 en el numerador y separar fracciones.
Empezamos con:
Reescribimos el del numerador como :
Y separamos la fracción:
El primer término simplifica:
Entonces… el primer término es por definición. El segundo término es , porque elevar al cuadrado una fracción equivale a elevar al cuadrado el denominador. Así que:
¡Bien! Por fin. Mi derivada y la de los artículos son la misma cosa.
¿Por qué importa esa forma alternativa?
Es simple coste computacional. Te lo dejo de tarea.
Por eso en el código del proyecto, la función diff_sigmoid está escrita así:
def diff_sigmoid(x: float) -> float:
return sigmoid(x) * (1 - sigmoid(x))En realidad, en backpropagation hago algo todavía mejor: como tengo guardada la activación después de aplicar sigmoid en el forward pass, puedo usarla directamente sin recalcular . La derivada se reduce a eso de arriba y no llamo a sigmoid en absoluto. Cero exponenciales en backpropagation.
Recapitulación
Antes de cerrar la nota, recapitulemos:
Sigmoid es . Aplasta cualquier número de la recta real al rango .
Su derivada es , que se puede deducir derivando la fórmula original con la regla del cociente y haciendo un truco algebraico para reescribirla de forma más útil.
Esa forma alternativa es eficiente porque, durante backpropagation, ya tenemos calculado del forward pass. Usar la forma ahorra recalcular exponenciales.
Sigmoid funciona bien para redes pequeñas pero tiene el problema del vanishing gradient en redes profundas, lo cual no afecta a este proyecto porque solo hay una capa oculta. Para redes más grandes se usa ReLU.
Con esto cerrado, la siguiente función que entró fue softmax, que sirve para la capa de salida y tiene una historia más rara que la de sigmoid. La cuento en NN-04 Softmax.